ETL Testing
What is ETL?
ETL is known for “extract, transform, and load.”
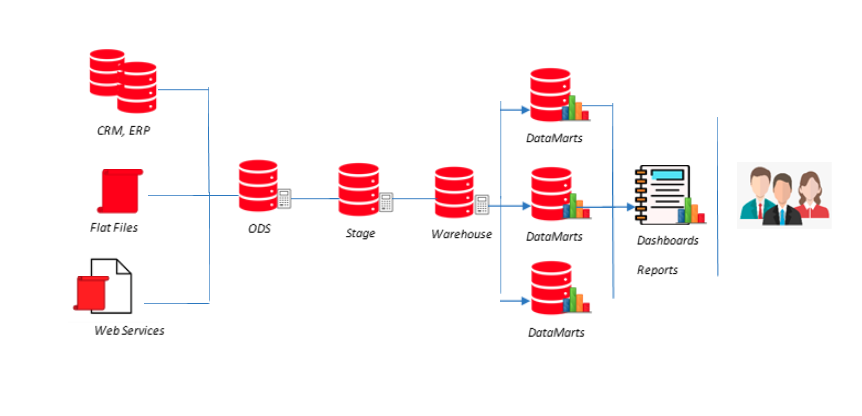
The procedure of ETL plays a crucial role in data integration strategies. Data Integration is a data preprocessing technique that involves combining data from multiple heterogeneous data sources into a coherent data store to provide a unified view of the data. These sources may include multiple data cubes, databases, or flat files.
ETL additionally makes it viable to migrate data between a spread of sources, destinations, and analysis tools. As a result, the ETL process plays a critical role in producing business intelligence and executing broader data management strategies.
What is ETL Testing?
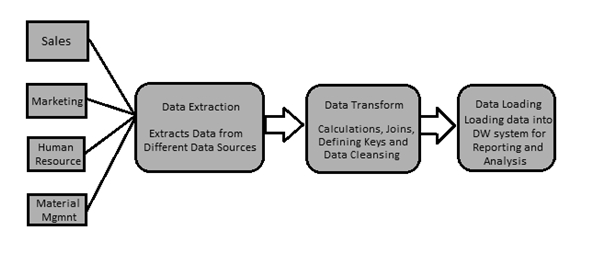
ETL testing is completed to ensure that the info has been loaded from an origin to its destination after fundamental business transformation. It also requires the verification of knowledge at various middle stages used between source and destination.
An ETL tool extracts the info from these heterogeneous data sources, transforms the information (like the implementation of business rule, data mapping, unique values, verifying and validating data fields, etc.), and loads it into a knowledge Warehouse.
What is ETL Testing Process?
ETL testing is carried out in different stages:
- Identifying data requirements & sources.
- Data Acquisition/Extraction.
- Source to target mapping
- Data checks/Verification on source data
- Packages and schema validation.
- Implement dimensional Modeling & business logic.
- Data integrity and quality checks in the target system
- Sample data comparison between the source and the target system
- Performance testing on data
- Build Reports.
ETL Testing Challenges
- Gathering data from Multiple &heterogeneous data sources
- Data extraction become tedious jobs because of size of data
- Complex data mining and cleaning data
- Complex data transformation logic
We believe in one stop point solution so we offer all type ETL Testing for our all clientage for the entire data problem.
Supported data technologies
Our solutions support below data platform for either legacy/Source or new/target system
- Amazon Redshift, DynamoDB, Simple Storage Service (S3), Athena
- EXASOL
- Cassandra
- Confluent KSQL
- Couchbase
- Cloudera
- Databricks in Azure
- Dremio
- Google BigQuery
- Hortonworks
- HP Tandem
- JSON
- Mainframe
- MapR
- MicroStrategy
- MongoDB
- Pivotal GreenPlum
- PostgreSQL
- Salesforce
- Sharepoint
- Snowflake
- Tableau
- Teradata, Aster
- Vertica
- Workday
- XML
- Apache Hadoop/Hive/Spark/Kafka
- Flat Files (delimited and fixed-width)
- Oracle (Oracle db, MySQL, Exadata)
- IBM (DashDB, BigInsights, DB2, Netezza, Informix, Cloudant, Cognos Analytics)
- Microsoft (Azure Synapse Analytics, SQL Server, PDW, SSAS, Access, Excel)
- SAP (HANA, IQ, ASE, SQL Anywhere, Business Objects)
- Azure Analysis Services, Data Lake Storage, Blob Storage, SQL Data Warehouse, SQL Database

